출처: https://hpbn.co/building-blocks-of-udp/
Networking 101: Building Blocks of UDP - High Performance Browser Networking (O'Reilly)
What every web developer must know about mobile networks, protocols, and APIs provided by browser to deliver the best user experience.
hpbn.co
[3장 UDP의 구성요소]
1. Null 프로토콜 서비스
2. UDP 및 네트워크 주소 변환기
1) 연결 상태 시간 초과
2) NAT 트래버설
3) STUN, TURN, 그리고 ICE
3. UDP 최적화
3장 UDP
- UDP 개요
- UDP(User Datagram Protocol)
=> 1980년 8월, Jon Postel에 의해 추가됨
=> TCP/IP 원래 도입 이후, TCP와 IP가 분리될 시점에 도입됨
- UDP의 특징
=> 새로운 기능을 추가하기보다 기존 기능을 생략하는 것이 핵심
=> TCP에서의 불필요한 기능을 제거하여 "null protocol"로 불림
=> RFC 768에 정의되며, 매우 간결한 프로토콜 (요약하면 냅킨에 적을 수 있을 정도)
- UDP의 대표적인 활용 사례: DNS
=> 사람이 이해하기 쉬운 도메인 이름을 해당 IP 주소로 변환
=> 데이터 교환 전에 반드시 수행되어야 하는 과정
- 브라우저에서의 UDP 활용 제한
=> 과거에는 UDP가 브라우저에서 사용되는 전송 프로토콜이 아니었음
=> 페이지나 애플리케이션에서 직접 접근할 수 없었음
- WebRTC의 등장과 UDP
=> IETF 및 W3C에서 공동 개발한 Web Real-Time Communication (WebRTC) 표준
=> 음성/영상 통화 및 기타 P2P(피어 투 피어) 통신을 브라우저에서 지원
=> WebRTC를 통해 UDP가 브라우저의 주요 전송 프로토콜(first-class transport)로 격상됨
=> 클라이언트 측 API를 통해 직접 사용 가능
- UDP에서의 D: Datagram
- Datagram
=> 독립적인 데이터 단위
=> 이전 통신 기록 없이 목적지까지 전달될 수 있음
=> 출발지부터 목적지까지 라우팅에 필요한 모든 정보를 포함
- Datagram ∈ Packet
1) Packet: 모든 형식화된 데이터 블록을 포함하는 일반적인 용어
2) Datagram: 신뢰성이 보장되지 않는 서비스(예: UDP)에서 사용되는 패킷을 의미
- UDP와 Datagram
=> UDP는 신뢰성 없는 전송을 제공하므로, 패킷이 아닌 Datagram이라는 용어를 사용
=> UDP의 U는 "User" 대신 "Unreliable"을 사용해 Unreliable Datagram Protocol이라고도 불림
* 데이터 손실 및 오류 감지가 불가능하며, 실패 알림이 제공되지 않음
1. Null 프로토콜 서비스
- UDP는 Null Protocol
- UDP가 "Null Protocol"로 불리는 이유
=> UDP를 이해하려면 먼저 한 단계 아래 계층인 IP(Internet Protocol)를 알아야 함
=> UDP와 TCP는 모두 IP 위에서 동작
- IP 계층의 역할
=> 출발지 → 목적지로 데이터그램(datagram)을 전달하는 것이 주요 기능
=> 데이터를 IP 패킷으로 캡슐화하여 전달 (출발지/목적지 주소 및 라우팅 정보 포함)
- IP의 신뢰성 부족
=> 데이터 전송에 대한 보장 없음 (전송 실패 시 알림 제공 안 됨)
=> 네트워크 혼잡, 높은 부하 등의 이유로 IP 패킷이 중간에서 손실될 수 있음
=> 상위 계층(예: TCP)이 이를 감지하고 복구할 책임을 가짐
=> UDP는 이러한 복구 기능을 제공하지 않으므로 "null protocol"로 불림
- UDP의 패킷 구조
- UDP 패킷 구조
=> 사용자 데이터를 UDP 패킷으로 캡슐화하여 전송
=> 추가되는 4가지 필드
* UDP는 IP 위에서 동작하며, 사용자 데이터를 UDP 패킷으로 감싸고 여기에 몇 가지 추가 정보를 포함
1) 출발지 포트 (source port)
2) 목적지 포트 (destination port)
3) 패킷 길이 (length)
4) 체크섬 (checksum)
- UDP의 최소한의 기능
=> IP 패킷이 목적지에 도착하면, UDP가 패킷을 해제하고 포트 번호를 기준으로 애플리케이션에 전달
=> 추가적인 기능 없이 단순한 데이터 전달 역할 수행
- UDP 필드는 optional
=> 출발지 포트와 체크섬 필드는 선택적(optional)
=> IP 패킷 자체에 헤더 체크섬이 존재함
=> 애플리케이션이 UDP 체크섬을 생략할 수 있으며, 오류 감지 및 수정은 상위 계층에서 담당
- UDP의 주요 "비기능(non-services)" 특징
1) [메시지전송 보장없음] 확인, 재전송 또는 시간 초과가 없음
2) [배송순서 보장불가] 패킷 시퀀스 번호 없음, 재정렬 없음, HOL(Head-of-Line) 차단 없음
* HOL(Head-of-Line) 차단 없음? 네트워크에서 한 개의 패킷이 지연되더라도 다른 패킷들의 처리가 지연되지 않음
3) [연결상태 추적없음] 연결 설정 또는 해제 상태 머신이 없음
4) [혼잡제어 없음] 네트워크 및 클라이언트 피드백 메커니즘 없음


- UDP 기반 프로토콜 설계 시 고려할 점
- TCP와 UDP의 메시지 처리 방식 차이
1) TCP
=> 바이트 스트림(byte-stream) 기반 프로토콜
* 바이트 스트림: 데이터를 연속적인 바이트 스트림으로 처리 (즉, 전송된 데이터가 하나의 긴 흐름처럼 처리)
=> 여러 패킷에 걸쳐 데이터를 분할하여 전송, 명확한 메시지 경계(boundary) 없음
=> 연결 상태 유지 (각 끝단에서 상태 정보 저장)
=> 순서 보장 및 재전송 지원 (패킷 손실 시 재전송, 순서 정렬)
2) UDP
=> 데이터그램(datagram) 기반 프로토콜 → 개별 메시지가 명확한 경계를 가짐
=> 하나의 IP 패킷에 하나의 UDP 데이터그램이 포함됨
=> 조각(fragmentation) 불가능 → 패킷 크기를 고려해야 함
- UDP의 특성 및 활용
=> 상태를 유지하지 않는(stateless) 단순한 프로토콜
=> 애플리케이션이 직접 프로토콜 설계 가능 (TCP보다 자유로움)
=> 부트스트래핑(bootstrapping) 용도로 적합
* 부트스트래핑? 시스템이나 네트워크가 처음 시작할 때 필요한 초기 설정을 자동으로 수행하는 과정
* UDP가 부트스트래핑 용도로 적합한 이유? UDP의 빠르고 간단한 특성이 시스템이나 서비스가 초기화될 때 필요한 최소한의 통신에 유리하기 때문
- UDP 기반 프로토콜 설계 시 고려할 점
=> NAT(Network Address Translation) 문제 → 중간 네트워크 장비(예: 라우터, 방화벽)와의 호환성 고려 필요
=> TCP를 단순히 복제하는 것은 위험 → TCP는 수십 년 동안 최적화된 알고리즘과 상태 관리 메커니즘을 갖춤
=> UDP만의 특성을 잘 활용해야 함 → 잘못 설계하면 결국 미완성된 TCP의 열화판이 될 위험이 있음
2. UDP 및 네트워크 주소 변환기
- NAT 도입 배경
- IPv4 주소 한계
=> IPv4 주소는 32비트 길이 → 최대 약 42억 개(4.29 billion)의 고유 IP 주소 제공
=> 1990년대 초, 인터넷 사용자의 급격한 증가로 고유 IP 주소 부족 문제 발생
- NAT(Network Address Translator) 도입 배경
=> 1994년 RFC 1631에서 제안된 임시 해결책
=> 하나의 공인(public) IP 주소를 여러 사설(private) IP 주소와 매핑하여 IP 주소 재사용 가능
=> 네트워크 가장자리(edge)에 NAT 장비를 배치하여 IP 및 포트 정보를 변환
- NAT의 동작 방식
=> NAT 장치는 로컬 IP + 포트 → 공인 IP + 포트 매핑 테이블을 유지
=> 동일한 사설 IP 주소 공간을 여러 네트워크에서 재사용 가능
=> 결과적으로 IPv4 주소 고갈 문제 해결
- NAT의 예상치 못한 영구적 영향
=> 원래는 임시 해결책이었으나, 인터넷 인프라의 핵심 요소로 자리 잡음
=> 기업/가정용 프록시, 라우터, 보안 장비, 방화벽 등 다양한 네트워크 장비에서 표준적으로 사용
=> 현재는 NAT 없이 IPv4 네트워크를 운영하기 어려운 상황이 됨
- 사설 IP 주소 범위 (Reserved Private Network Ranges)
=> IANA(인터넷 할당 번호 기관)에서 사설 네트워크용으로 예약한 IP 주소 범위
=> NAT(Network Address Translation) 장치 뒤에서 주로 사용됨
=> 특징
1) 일반적으로 공유기에서 내부 네트워크에 할당하는 IP 주소
2) 외부 네트워크와 통신할 때 NAT 장치가 공인 IP로 변환
3) 공인 네트워크에서는 위의 사설 IP 주소를 사용할 수 없음 (라우팅 불가)


- 연결종료 과정이 없는 UDP의 세션유지 방법
- NAT와 UDP의 문제점
=> NAT 장치는 연결 상태(connection state)를 기반으로 라우팅 테이블을 유지함
=> UDP는 연결 상태를 유지하지 않음 → NAT와의 근본적인 불일치 발생
=> NAT가 여러 계층으로 중첩될 경우 UDP 패킷 전달이 더욱 어려워짐
- TCP와 UDP의 차이점
1) TCP
=> 3-way 핸드셰이크로 연결 수립
=> 명확한 연결 종료 절차 존재
=> NAT 장치는 이 과정에서 상태를 추적하며 필요할 때 라우팅 테이블을 생성 및 삭제
2) UDP
=> 핸드셰이크(연결 수립) 없음
=> 연결 종료 과정 없음 → NAT가 언제 기록을 삭제해야 할지 알 수 없음
- UDP 라우팅 문제
=> 아웃바운드 UDP 트래픽 전달은 문제가 없음
=> 응답 패킷을 올바르게 전달하려면 NAT의 변환 테이블에 해당 UDP 흐름 정보가 필요
=> 하지만 UDP는 기본적으로 상태를 유지하지 않으므로, NAT가 이를 별도로 관리해야 함
- UDP 세션 유지 방법
=> NAT 장치는 UDP 연결이 종료되지 않는 한, 일정 시간 동안만 라우팅 기록을 유지
=> UDP에는 연결 종료 신호가 없으므로, 특정 시간이 지나면 NAT가 자동으로 기록을 삭제
=> UDP 세션을 장시간 유지하려면 Keepalive 패킷을 주기적으로 전송하여 타이머를 리셋
=> NAT 장치의 타임아웃 설정은 제조사, 모델, 버전에 따라 다름
* 명확한 기준이 없음
- TCP와 NAT의 타임아웃 문제
=> TCP는 명확한 핸드셰이크(handshake) 및 연결 종료(termination) 절차가 존재
=> 따라서 NAT 장치가 추가적인 TCP 타임아웃을 설정할 필요는 없음
- 실제 NAT 장치의 동작 방식
=> 많은 NAT 장치는 TCP와 UDP에 동일한 타임아웃 로직을 적용
=> 이로 인해 TCP 세션도 일정 시간이 지나면 강제 종료될 수 있음
- TCP 연결 유지 방법
=> 일부 NAT 환경에서는 TCP 세션 유지에도 Keepalive 패킷이 필요
=> TCP 연결이 예상치 못하게 끊어질 경우 NAT 장치의 타임아웃이 원인일 가능성이 큼
- NAT 우회(Traversal) 기술
- NAT 환경에서의 연결 문제
=> NAT 장치는 예측하기 어려운 연결 상태 처리 문제를 야기
=> P2P 애플리케이션(VoIP, 온라인 게임, 파일 공유 등)에서 UDP 연결 자체를 성립하기 어려움
* P2P 애플리케이션은 클라이언트이자 서버 역할을 동시에 수행해야 하므로 직접적인 양방향 통신이 필수적
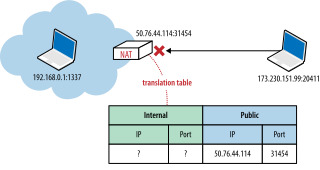
- 내부 클라이언트의 공인 IP 주소 인식 문제
=> 내부 클라이언트는 자신의 사설 IP 주소만 알며, 공인 IP 주소를 모름
=> NAT 장치는 UDP 패킷의 출발지 IP 및 포트를 재작성(rewriting)
=> 애플리케이션이 자신의 사설 IP 주소를 외부 피어(peer)에게 전달하면 연결이 실패함
=> 즉, NAT가 완전히 투명한(transparent) 변환을 수행하지 않음
* 애플리케이션이 직접 공인 IP 주소를 알아야 함
- UDP 패킷 전달 문제
=> 공인 IP를 안다고 해도 UDP 통신이 원활히 이루어지는 것은 아님
=> NAT 장치는 공인 IP로 들어오는 패킷을 내부 목적지 IP 및 포트로 변환해야 함
=> 하지만 NAT 테이블에 해당 목적지 정보가 없다면, 패킷은 그냥 폐기(drop)됨
=> 기본적으로 NAT는 단순한 패킷 필터 역할을 함
=> NAT가 내부로 패킷을 전달하려면 사용자가 포트 포워딩(port forwarding) 등의 설정을 직접 해야 함
- 클라이언트 애플리케이션과 NAT
=> 내부 네트워크에서 상호작용을 시작하고 그 과정에서 필요한 변환 레코드를 설정하는 클라이언트 애플리케이션은 문제가 되지 않음
=> 하지만 NAT가 있는 상태에서 P2P 애플리케이션에서 인바운드 연결(서버 역할)을 처리하는 경우 문제가 발생하는 것임
- NAT 우회(Traversal) 기술
=> NAT와 UDP의 불일치를 해결하기 위해 다양한 우회 기술이 필요
=> 대표적인 NAT Traversal 기술: STUN, TURN, ICE
- STUN, TURN, ICE
| 특징 | 동작 방식 | 단점 | |
| STUN | Session Traversal Utilities for NAT - RFC 5389에 정의된 프로토콜 - 클라이언트가 자신의 공인 IP 및 포트를 확인하는 데 사용 * 호스트 애플리케이션이 NAT의 존재를 감지하고, 할당된 공인 IP 및 포트 정보를 확인할 수 있도록 도와줌 |
1) 애플리케이션이 STUN 서버의 IP를 DNS 조회 또는 수동 설정으로 확보 2) STUN 서버에 바인딩 요청(binding request) 전송 3) STUN 서버가 클라이언트의 공인 IP 및 포트 정보를 응답 4) NAT 테이블에 해당 정보가 기록되므로, 이후 들어오는 패킷이 내부 호스트로 전달 가능 5) Keepalive 핑(ping) 메커니즘을 통해 NAT 타임아웃 방지 |
- 모든 NAT 환경에서 동작하지 않음 (일부 네트워크 토폴로지에서 실패) - 방화벽 또는 네트워크 장치가 UDP 트래픽을 차단할 경우 STUN이 무용지물 |
| TURN | Traversal Using Relays around NAT - RFC 5766에 정의된 프로토콜 - 중계 서버를 통해 통신을 우회 - STUN이 실패할 경우 대체(fallback) 방법으로 사용 - UDP가 차단되면 TCP로 자동 전환 가능 - 공용 릴레이 서버(TURN 서버)를 이용해 데이터 전달 |
1) 두 클라이언트가 같은 TURN 서버에 연결 요청(allocate request) 전송 2) TURN 서버에서 권한(permission) 협상 진행 3) 각 클라이언트가 TURN 서버로 데이터를 전송 4) TURN 서버가 데이터를 중계(relay)하여 피어 간 통신 지원 |
- P2P 방식이 아님 (모든 트래픽이 TURN 서버를 경유해야 함) - TURN 서버 운영 비용이 높음 (대역폭과 처리 용량 필요) - 따라서 TURN은 최후의 방법(last resort)으로 사용 |
| ICE | Interactive Connectivity Establishment - RFC 5245에 정의된 프로토콜 - STUN과 TURN을 조합하여 최적의 경로를 찾는 방식 => 가장 효율적인 NAT 우회(NAT Traversal) 방법을 찾는 메커니즘 - P2P 애플리케이션의 안정적인 연결을 지원 |
1) 직접 연결 시도 (가능하면 NAT 우회 없이 P2P 통신) 2) STUN 사용 (공인 IP 및 포트 확인 후 NAT 우회) 3) TURN 사용 (STUN이 실패할 경우 릴레이 서버를 통해 중계) |
- |


- ICE의 장점
=> 최적의 연결 방법을 자동으로 선택하여 최소한의 리소스로 NAT 우회
=> 다양한 네트워크 환경에서 UDP 기반 P2P 연결의 성공률을 높임
=> STUN, TURN을 단독으로 사용할 때 발생하는 문제를 보완
- P2P 애플리케이션 개발 시 ICE 활용 방법
=> 직접 ICE, STUN, TURN을 구현하는 것은 복잡하고 어려운 작업
=> 기존 플랫폼 API 또는 타사 라이브러리를 활용하는 것이 효율적
=> ICE의 동작 원리를 이해하면 적절한 설정과 구성이 가능

+ 쉽게 풀어쓴 STUN 동작방식
STUN은 내가 어디에 있는지 알려주는 서비스라고 생각할 수 있습니다.
=> NAT 뒤에 있는 클라이언트가 외부에서 자신을 어떻게 인식할지를 알려주고, 그 정보를 바탕으로 다른 클라이언트와의 연결을 가능하게 만듭니다.
=> Keepalive ping은 연결이 끊어지지 않도록 유지해주는 역할을 합니다.
1. 애플리케이션이 STUN 서버의 IP를 확보
- 애플리케이션(예: WebRTC나 VoIP)은 STUN 서버의 IP 주소를 알게 됩니다.
- 이 정보는 DNS를 통해 자동으로 찾거나, 수동으로 설정할 수 있습니다. STUN 서버는 NAT(Network Address Translation)을 우회하는 데 필요한 공인 IP 주소와 포트 정보를 제공합니다.
2. STUN 서버에 바인딩 요청 전송
- 애플리케이션이 STUN 서버에 바인딩 요청(binding request)을 보냅니다.
- 이 요청은 STUN 서버에 "내가 어디에 있나?"라는 질문을 하는 것과 같습니다.
- 이 요청은 클라이언트가 자신을 인터넷 상에서 어떻게 식별하는지 확인하려는 목적입니다.
3. STUN 서버가 공인 IP 및 포트 정보를 응답
- STUN 서버는 요청을 받은 후, 클라이언트가 인터넷 상에서 어떤 IP 주소와 포트 번호로 보이는지를 알려줍니다.
- 즉, NAT 뒤에 있는 클라이언트가 외부에서 어떻게 보이는지 알려주는 것입니다.
- 이 정보를 통해 클라이언트는 NAT를 우회하여 다른 클라이언트와 연결할 수 있게 됩니다.
4. NAT 테이블에 해당 정보가 기록됨
- 클라이언트가 요청을 보내면, NAT 장치(라우터)는 그 정보를 NAT 테이블에 기록합니다.
- 이 테이블에 기록된 정보를 바탕으로, NAT 장치는 외부에서 들어오는 패킷을 올바른 내부 호스트(즉, 클라이언트)로 전달할 수 있게 됩니다.
- 이는 외부에서 들어오는 트래픽을 올바른 내부 IP 주소로 포워딩하는 과정입니다.
5. Keepalive 핑(ping) 메커니즘
- NAT 장치에는 타임아웃이 설정되어 있습니다.
- 일정 시간이 지나면, NAT 테이블에서 연결 정보가 삭제될 수 있습니다.
- 이를 방지하기 위해, 클라이언트는 일정 주기로 Keepalive ping을 보내서 NAT 장치에 "내 연결을 유지해줘!"라고 알려줍니다.
- 이렇게 하면 NAT 장치가 연결 정보를 오래 유지하게 되어, 클라이언트 간의 통신이 끊어지지 않게 됩니다.
+ 쉽게 풀어쓴 TURN 동작방식
TURN (Traversal Using Relays around NAT)은 STUN으로 직접 연결할 수 없는 경우, 중계 서버를 사용하여 데이터를 전송하는 방식입니다.
=> 클라이언트들은 TURN 서버를 통해 데이터를 보내고, TURN 서버는 그 데이터를 받아서 다른 클라이언트에게 전달합니다.
=> 이 과정은 클라이언트 간의 직접 통신이 불가능할 때 데이터를 주고받을 수 있게 도와주는 역할을 합니다.
=> 그렇다면, TURN 서버는 연결이 어려운 클라이언트들 간의 데이터를 중계하는 중요한 역할을 하는 거예요.
1. 두 클라이언트가 같은 TURN 서버에 연결 요청 전송
- 두 클라이언트가 서로 직접 연결할 수 없을 때, 각 클라이언트는 TURN 서버에 연결을 요청합니다. 이 요청은 allocate request라고 불리며, TURN 서버에 "나는 여기에 있어요. 연결을 시작할 수 있도록 도와주세요"라는 의미입니다.
- 즉, 클라이언트는 TURN 서버에게 데이터를 중계해달라고 요청하는 거죠.
2. TURN 서버에서 권한(permission) 협상 진행
- TURN 서버는 클라이언트들이 서로 안전하게 데이터를 주고받을 수 있도록 권한(permission)을 협상합니다.
- TURN 서버는 각 클라이언트에게 전송할 수 있는 고유의 주소와 포트 번호를 할당하고, 이를 통해 중계 역할을 할 준비를 합니다.
3. 각 클라이언트가 TURN 서버로 데이터를 전송
- 이제 각 클라이언트는 TURN 서버로 데이터를 전송합니다. 이 데이터를 TURN 서버가 받아서 중계할 준비를 합니다.
- 클라이언트는 직접 연결할 수 없으므로, TURN 서버를 통해 모든 데이터를 전송합니다.
4. TURN 서버가 데이터를 중계하여 피어 간 통신 지원
- TURN 서버는 클라이언트로부터 받은 데이터를 다른 클라이언트에게 중계(relay)합니다.
- 즉, TURN 서버가 중간자 역할을 하며, 데이터를 A 클라이언트에서 B 클라이언트로 전달하는 역할을 합니다. 이렇게 해서 두 클라이언트 간의 연결이 가능해집니다.
+ 쉽게 풀어쓴 ICE 동작방식
ICE (Interactive Connectivity Establishment)는 네트워크에서 두 클라이언트 간에 직접 연결을 시도하는 방법을 다룹니다.
=> 이 과정은 주로 WebRTC나 VoIP와 같은 실시간 통신에서 사용됩니다.
=> 이 전체 과정은 클라이언트 간의 통신을 원활하게 하기 위한 과정입니다.
=> 각 단계는 가능한 한 직접 연결을 시도하고, 실패하면 점차 더 복잡한 방식으로 연결을 시도합니다.
1. 직접 연결 시도 (P2P 통신)
- 이 단계에서는 두 클라이언트가 가능한 한 직접 통신하려고 시도합니다.
- 즉, 두 클라이언트의 컴퓨터가 서로 직접 연결할 수 있다면, NAT(네트워크 주소 변환)를 우회할 필요 없이 P2P(점대점) 통신이 이루어집니다.
- 하지만 대부분의 경우, 두 클라이언트가 동일한 로컬 네트워크에 있지 않거나 방화벽이나 라우터로 인해 직접 연결이 어려운 경우가 많습니다.
2. STUN 사용
- 만약 직접 연결이 실패하면, STUN (Session Traversal Utilities for NAT) 서버를 사용해 NAT를 우회하려고 시도합니다.
- STUN 서버는 클라이언트의 공인 IP와 포트 번호를 확인하는 데 사용됩니다. 이 정보는 NAT 뒤에 있는 클라이언트가 인터넷 상에서 어떻게 보이는지를 알려줍니다.
- STUN을 통해 클라이언트는 NAT 뒤에서 외부와 통신할 수 있는 방법을 알게 되고, 이를 이용해 다른 클라이언트와 연결을 시도합니다.
3. TURN 사용
- STUN이 실패하거나 NAT 우회가 불가능한 경우, TURN (Traversal Using Relays around NAT) 서버를 사용합니다.
- TURN 서버는 두 클라이언트 간의 연결을 중계해주는 역할을 합니다. 즉, 두 클라이언트가 서로 직접 통신할 수 없을 때, 중간 서버를 통해 데이터를 전달합니다.
- TURN은 성능에 영향을 미칠 수 있지만, 최후의 방법으로 사용됩니다.
- Google의 libjingle
=> 오픈 소스 C++ 라이브러리 (P2P 애플리케이션 개발 지원)
=> STUN, TURN, ICE 프로토콜을 자동 처리
=> Google Talk 등 P2P 기반 애플리케이션에서 사용됨
- 실제 STUN vs. TURN 성능 데이터
=> 92%의 경우 STUN을 사용하여 직접 연결 가능
=> 8%의 경우 TURN을 사용하여 릴레이 필요 (TURN의 필요성)
=> STUN만으로는 일부 사용자들이 직접 P2P 연결을 수립하지 못함
=> 안정적인 P2P 서비스 제공을 위해 TURN 서버가 필요
=> TURN은 최후의 대안(fallback)으로 사용되지만 필수적인 요소
3. UDP 최적화
- UDP 최적화
=> TCP는 기본적으로 흐름 제어, 혼잡 제어 및 혼잡 회피 기능을 제공하지만, UDP는 이러한 기능이 없어 애플리케이션이 직접 구현해야 함
=> 혼잡에 민감하지 않은 UDP 애플리케이션은 네트워크를 쉽게 과부하 상태로 만들 수 있음
=> 심각한 경우 네트워크 성능 저하 및 혼잡 붕괴로 이어질 수 있음
- UDP 애플리케이션 설계 시 고려해야 할 사항 (RFC 5405 기반)
1) 애플리케이션은 광범위한 인터넷 경로 조건을 허용 해야 합니다
2) 응용프로그램은 전송 속도를 제어 해야 합니다 . 애플리케이션은 모든 트래픽에 대해 혼잡 제어를 수행 해야 합니다
3) 애플리케이션은 TCP와 유사한 대역폭을 사용해야 합니다
4) 손실 후에는 애플리케이션이 재전송 카운터를 철회 해야 합니다
5) 애플리케이션은 경로 MTU를 초과하는 데이터그램을 보내면 안 됩니다
6) 애플리케이션은 데이터그램 손실, 복제, 재정렬을 처리 해야 합니다
7) 애플리케이션은 최대 2분까지의 배송 지연을 견뎌낼 수 있어야 합니다
8) 애플리케이션은 IPv4 UDP 체크섬을 활성화 해야 하며, IPv6 체크섬을 활성화 해야 합니다
9) 필요할 경우 애플리케이션은 keepalives를 사용할 수 있습니다(최소 간격 15초)
- UDP 기반 전송 프로토콜 설계 시 주의사항
=> 많은 연구와 계획이 필요하므로 신중하게 설계해야 함
=> NAT 트래버설, 공정한 네트워크 자원 공유 등을 고려한 기존 라이브러리나 프레임워크 활용을 추천
=> WebRTC는 이러한 요구사항을 충족하는 대표적인 프레임워크임
관련해서 볼만한 참고자료
https://www.youtube.com/watch?v=8jryUH6xmjU